Classic DC and M-LAG
In the pervious post we talked about BGP in Data Center and how it is a topic of discussion in between the DC and the SP arenas.
In this post I will start explaining some classic DC design and laying its shortage which will engage the SP gurus with us, as well it will make sure that we all on the same page for the DC gurus.
So let's start to engage the SP gurus with basic enterprise and DC concepts.
Basic Ethernet world in LAN would go like this switches forward frames based on detestation MAC address, the MAC address learning is dynamic where switches listen to the source MAC address in each frame and store it in there mac-address-table. In the meantime switches flood all the BUM traffic (broadcast, multicast, unknown unicast) to all interfaces in that VLAN except the one it received it. As for the segmentation we have 4K VLANs (4096 VLAN) where access port generally carries one untagged traffic belong to one VLAN and trunk port carries tagged traffic from many VLANs, and because of BUM traffic way of handling we run loop avoidance protocol that blocks any redundant path, Multi-Spanning tree MSTP is most popular one as it scale and standard one in compare to other flavors of STP.
But do you think a design based on only on this concept would be sufficient to run DC?
Nn fact, no proper DC would run using this basic Ethernet technology, and even the tiny small DCs that still has that are actively thinking of other solutions. Can you spot the issues they are facing using that simple diagram (you can multiply the number of servers, switches and links as you want), in here is a typical 3 tier DC design
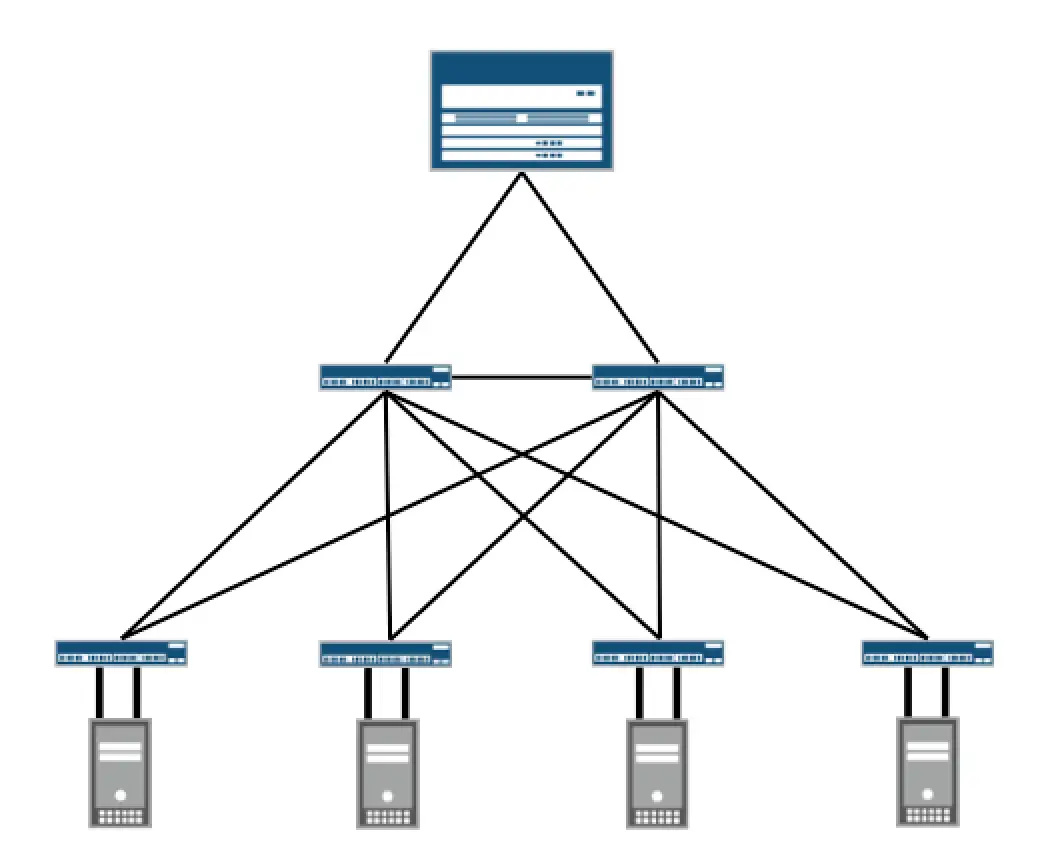
here are some of the issues not even all of them
1- running spanning tree between your switches by itself is a problem, not only because spanning tree coverage is so slow for nowadays networks but also because the best flavor you would get from spanning tree is MSTP which offer manual fixed load sharing, where you manually set group of VLANS to be forwarded over one interface while blocked over the other, which only works well if you know from the begging the traffic in first instance (group of VLANs is mapped to Instance) would always be equal to the traffic in the other instance.
In other words, you aren't utilizing your links in any proper way plus we have complexity in calculating the subscription ratio for the access switch in the virtualized environment in fact spanning tree has been moved out DC (as well in many enterprises), STP has been changed from a protocol that runs between switches blocking paths, avoiding L2 loops to be a protocol that you run only toward the access for protection.
2- 4k VLANS for segmentation won’t scale by any meaning once we start to talk about it hosting, multitenant and the basic virtualized servers (where each VM reside in one VLAN and connected to your switch over trunk port).
Also, think of the VLAN that each interface can actually forward in the data plan as some vendor might claim that each trunk interface support of simultaneously 4k VLAN but when it come to forwarding you would get less number of VLAN.
What about double tagging QinQ where the outer/service VLAN would be carrying a group of inner/customer VLAN?
That could be solution for that part and some DCs actually use it but QinQ doesn’t offer anything in related switches maintaining forwarding information for every VM (MAC address) as forwarding still based on MAC address learned by listening and flooding.
3- What about scaling and the size of the broadcast domain, how many server would we put in one VLAN? When it come to virtualize environment we have to think also about the amount of BUM (broadcast, multicast, unknown unicast) traffic handled by the hypervisor.
4- What about configuration where you manage each device individually, DC gurus for sure knows the hassle to provision a VLAN,IP to the server/application team to the level DC gurus feels they are like working in the telephone switch in the 1940s where the telephone operate manually connect the cable between the to side of the phone call but here in DC instead of cable it would be VLAN, I know some DC guys would make most of the server connecting interface as trunk to avoid this hassle.
5- What about the number of hops between servers? Is it all the time the same number of hops (also latency)? That’s complicated and based on the traffic patterns and the SVI/RVI/IRB (L3 interface for VLAN based on each vendor implementations) location but the point is this hard to be said and guaranteed to be the same
I can keep on and on adding more issues that you might face if you build your DC that way regardless of your switching vendor.
Evolutions from that design have created 2 tires flavor of it (by collapsing the core and aggregation layer) which offered better performance but still doesn’t satisfy today DCs, but don’t get me wrong I am not saying this is very horrible technology that we should stop using them in any kind of network , of course, not this basic switching technology was used in the past and is going to be used in the future in many small enterprise kinds of network; what I am saying is that today's DCs can't relay in such basic switching technology.
Is there any solutions that can be added to fix, yes there are many solutions to overcome these issues but once you start with any of them you would lose the open standard features you got from this classic Ethernet technology (only IP fabric is truly open stranded)
The first one is M-LAG which is VPC for CISCO, M-LAG for ARISTA and MC-LAG for JUNIPER

For the sake of simplicity I will name it M-LAG
Normally you can combine more than one Ethernet interface between two switches in one bundle, the bundle would be seen as one port from the control plan point of view and you would be able to load-balance the traffic per follow over the physical member (based on switch hashing). Although vendors name this bundle differently (aggregate interface, ether-channel ,..,etc) but the vendor can work together and you can add on top of it the standard LACP.
The M-LAG is a bit different as it runs between 3 switches where SW3 is not aware that the other side of the bundle is connected to different switches , for SW3 it is just a normal bundle SW1 and SW2 are aware of that and we call them the M-LAG peer.
This protocol can eliminate the need for STP in that segments in your network as well provide redundancy with load balancing
so server can be connected to two TORs (Top OF the Rack switches) also TOR would be connected to two aggregations and so on
But why many people like M-LAG? is it locking you with one vendor? Can the vendor interoperate together?
Not that much, the point is the M-LAG peers (SW1,SW2 in the diagram) has to be from the same vendor , but SW3 is not aware of that so it can be from any vendor that support basic Ethernet bundle.
The problem with M-LAG that all the vendor implementation are based on some idea but every vendor has his own way to run it and some have more features than the other.
In fact, M-LAG / MC-LAG /VPC is a very good protocol but not to build the whole DC based on it. still, won't scale that much, yes you may use many vendors in your DC but the extra configuration and the link between the peers (SW1 & SW2) might need extra consideration as it might create congestions and finally, the two peers have to be from the same vendor.
Check Also

